2022年3月3日
Voice Cloning experiment at Leapmind Hackdays (2022Q1)

Hello, this is Patrick. I am an engineering manager at Leapmind.
Recently, in our hackdays in January 2022, I thought up some fun ideas to experiment. This was done over 2-3 days. (About our past hackdays activity, please see this article)
The Idea
Most people are afraid of speaking foreign languages (eg. English). From what I understand, they lack the confidence and are afraid of making grammatical mistakes, or thinking that they have a funny accent.
But what if we can "simulate" what we would have sounded like, if we have perfect English capability? One solution is using voice cloning.
The Method
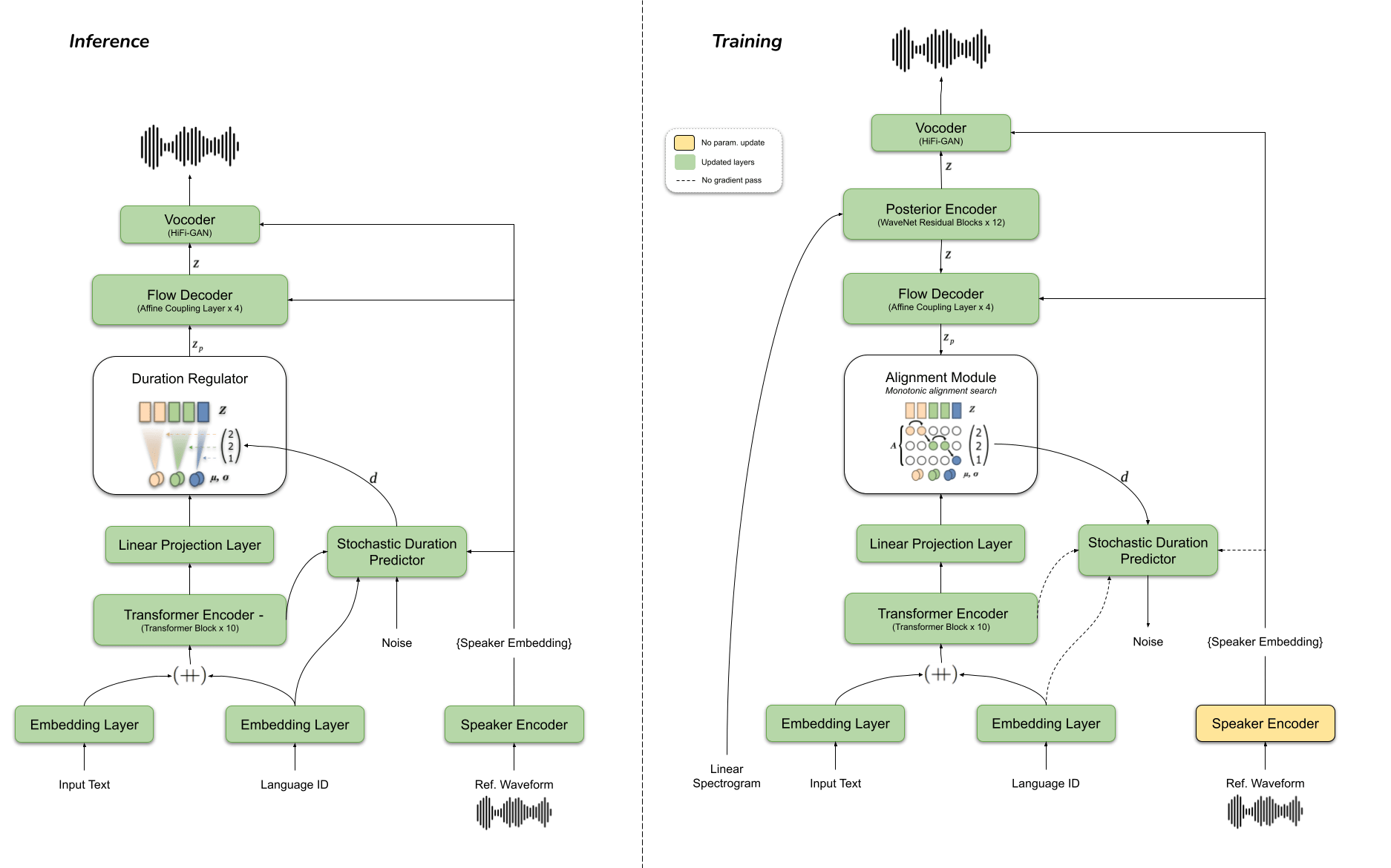
Recently, an impressive advance in voice cloning domain has been made -- it is called YourTTS. This model enables us to easily embed a new speaker's voice without training and with minimal data required. An example colab code is here.
Figure: TTS model architecture (source from coqui.ai)
The Data
One of the challenges with most machine learning projects is how to find relevant, high quality data. In this case, I asked a few leapmind employees' (including our CEO!) permission to use their voice sample as input data. Fortunately, we have a few video recordings of our internal presentations. These are mostly 05-30 min uninterrupted speeches of each presenter, which I can extract with the following steps below.
Additionally, for the text-to-speech part to work, a short speech (say -- a few sentences) should be prepared. Note that for custom names (company products, human names), the normal wording might fail so we have to "craft" a natural-sounding text with trial and error.
- find source reference data from old company presentation videos
- download as mp3/wav, then put into Audacity (audio editor)
- clean out other noises (other people’s voice, coughing, etc.)
- export as wav file
- normalize and sample with ffmpeg
- prepare “English text” file for AI to read
- run the prepared input data through YourTTS model to generate output .wav file.
The Result
I found that at the minimum, a 5-min sample speech can enable the TTS model to somewhat mimic the speaker's voice. However, to product high-quality output, a more varied and high-quality sample speech data is needed (more varied topics, vocabularies, and quiet background noises). Additionally, certain speakers can have a more pronouced speaking personality and tone that is more easily emulated.
Here is one example of the output... the speaker is our CEO!
English text used:
Since its inception in 2012, LeapMind has engaged in
research and development of software frameworks, algorithms, and hardware,
with a focus on embedded technologies, to solve business problems
with leading-edge machine learning technologies.
Conclusion
Since this is "a little fun mini-project" that took little time, I didn't expect the result to be good. However, the quality does surprise me since I only prepared minimum amount of data (less than 25 min speech) where usually a much larger set is required for speech projects.
Finally, I want to thank my colleagues who allow me to use their voice data for this experiment and the open-source community for allowing people like me to try out and tinker with the latest technologies.